There are two claims I’d like to make:
- LLMs can be used effectively1 for listwise document ranking.
- Some complex problems can (surprisingly) be solved by transforming them into document ranking problems.
I’ve primarily explored both of these claims in the context of using patch diffing to locate N-day vulnerabilities—a sufficiently domain-specific problem that can be solved using general purpose language models as comparators in document ranking algorithms. I demonstrated at RVAsec ‘24 that listwise document ranking can be used to locate the specific function in a patch diff that actually fixes a vulnerability described by a security advisory, and later wrote on the Bishop Fox blog in greater defense of listwise ranking by publishing a command-line tool implementation (raink) to prove the idea.
The key insight is that instead of treating patch diffing as a complex problem requiring specialized security engineering knowledge, you can reframe it as ranking diffs (documents) by their relevance to a security advisory (query), applying proven document ranking techniques from information retrieval.
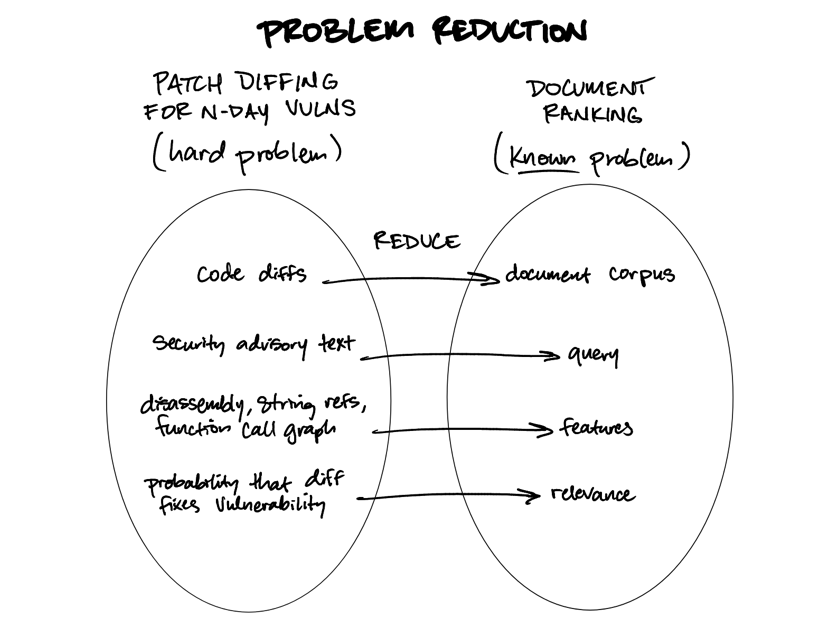
Using this technique, I proved at DistrictCon ‘25 that GPT-4o mini could locate a fixed vulnerability in a haystack of over 1600 changed (and stripped!) functions in a patch—costing only 5 minutes and 30 cents to do so2.
Document ranking can be applied to other offensive security problems, like identifying candidate functions for fuzzing targets (in addition to using them for auto-generating harnesses), or prioritizing potential injection points in a web application for deeper testing. A few potentially powerful improvements to this technique:
- Analyze the top N ranked results, and then apply the same ranking algorithm to the analyses.
- Make the ranked results verifiable; e.g., for N-day vulnerabilities, use an LLM to generate an automatically testable proof-of-concept exploit3.
Following Thomas Dullien’s FUZZING ‘24 keynote “Reasons for the Unreasonable Success of Fuzzing”, I’m inclined to give a similar talk—“Reasons for the Unreasonable Success of LLMs.”
-
A few others have explored the idea of document ranking using LLMs, but favored the computationally complex pairwise ranking method while noting the challenges of the more efficient but yet-unimplemented listwise ranking method. See Prompting-based Methods for Text Ranking Using Large Language Models (Dec ‘23) and Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting (Mar ‘24). ↩︎
-
See aforementioned DistrictCon talk for an example of
o3‑mini‑highsuccessfully generating an exploit for CVE-2024-53704, an authentication bypass in SonicWall firewalls. ↩︎